1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| import requests
import re
import hashlib
from lxml import etree
from PIL import Image
from io import BytesIO
class JWCSpider():
def __init__(self, username, password):
self.username = username
self.password = self.__md5preFix(password)
self.session = requests.session()
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Host': 'zhjw.scu.edu.cn',
'Referer': 'http://zhjw.scu.edu.cn/login',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36',
'Origin':'http://zhjw.scu.edu.cn',
}
def __md5preFix(self, password: str) -> str:
ins_md5 = hashlib.md5()
ins_md5.update(password.encode('utf-8'))
return ins_md5.hexdigest()
def __get_captcha(self):
url = 'http://zhjw.scu.edu.cn/img/captcha.jpg'
captcha_img = self.session.get(url).content
img = Image.open(BytesIO(captcha_img))
img = img.convert('L')
img.save('captcha.jpg')
captcha = str(input('验证码:'))
return captcha
def __tofile(self, content: str, filename: str = 'format.html'):
with open(filename, 'w', encoding='utf-8') as ofile:
ofile.write(content)
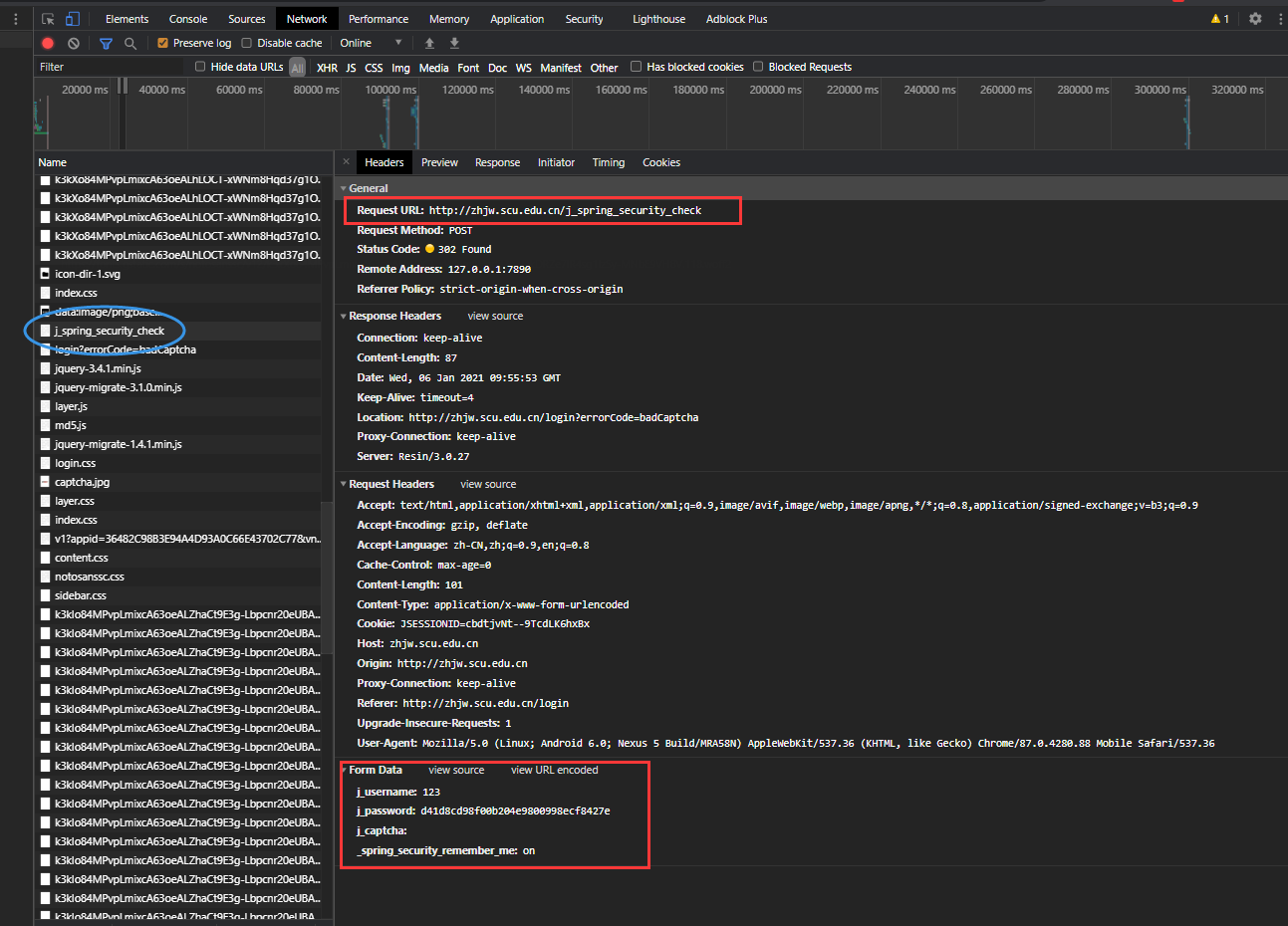
def login_in(self) -> str:
url = 'http://zhjw.scu.edu.cn/j_spring_security_check'
data = {
'j_username': self.username,
'j_password': self.password,
'j_captcha': self.__get_captcha()
}
try:
response = self.session.post(url, data = data, headers=self.headers)
except ConnectionError:
return ('error', '网络连接登录错误')
except TimeoutError:
return ('error', '访问超时登录错误')
isError = re.findall(r'errorCode=', response.content.decode('utf-8'))
if isError:
return ('error', '账号或者密码错误')
else:
return ('ok', '登录成功')
def get_planCompletion(self):
url = 'http://zhjw.scu.edu.cn/student/integratedQuery/planCompletion/index'
self.headers['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
self.headers['Referer'] = 'http://zhjw.scu.edu.cn/student/integratedQuery/course/courseSchdule/index'
response = self.session.get(url, headers=self.headers)
self.__tofile(response.text)
def get_courseTable(self):
url = 'http://zhjw.scu.edu.cn/student/courseSelect/thisSemesterCurriculum/ajaxStudentSchedule/curr/callback'
self.headers['Accept'] = '*/*'
self.headers['Referer'] = 'http://zhjw.scu.edu.cn/student/courseSelect/thisSemesterCurriculum/index'
self.headers['X-Requested-With'] = 'XMLHttpRequest'
response = self.session.get(url, headers=self.headers)
self.__tofile(response.text, "coursetable.json")
def get_courseSection(self):
url = "http://zhjw.scu.edu.cn/ajax/getSectionAndTime"
self.headers["Accept"] = "application/json, text/javascript, */*; q=0.01"
self.headers["Referer"] = "http://zhjw.scu.edu.cn/student/courseSelect/thisSemesterCurriculum/index"
self.headers['X-Requested-With'] = 'XMLHttpRequest'
response = self.session.post(url, headers=self.headers, data={"planNumber":"", "ff": "f"})
self.__tofile(response.text, "format.json")
def get_studentPic(self):
url = 'http://zhjw.scu.edu.cn/main/queryStudent/img?715.0'
self.headers['Accept'] = 'image/avif,image/webp,image/apng,image/*,*/*;q=0.8'
self.headers['Referer'] = 'http://zhjw.scu.edu.cn/student/courseSelect/thisSemesterCurriculum/index'
stdPic = self.session.get(url, headers=self.headers).content
img = Image.open(BytesIO(stdPic))
img.save('student.jpg')
def get_name(self):
url = 'http://zhjw.scu.edu.cn/student/rollManagement/rollInfo/index'
self.headers['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
self.headers['Referer'] = 'http://zhjw.scu.edu.cn/'
response = self.session.get(url, headers=self.headers)
res = re.findall(r'title=".*的照片', response.content.decode('utf-8'))
print(res[0][7:].replace('的照片', ''))
def main():
check = JWCSpider('studentid', 'password')
print(check.login_in())
check.get_studentPic()
check.get_courseSection()
if __name__ == '__main__':
main()
|